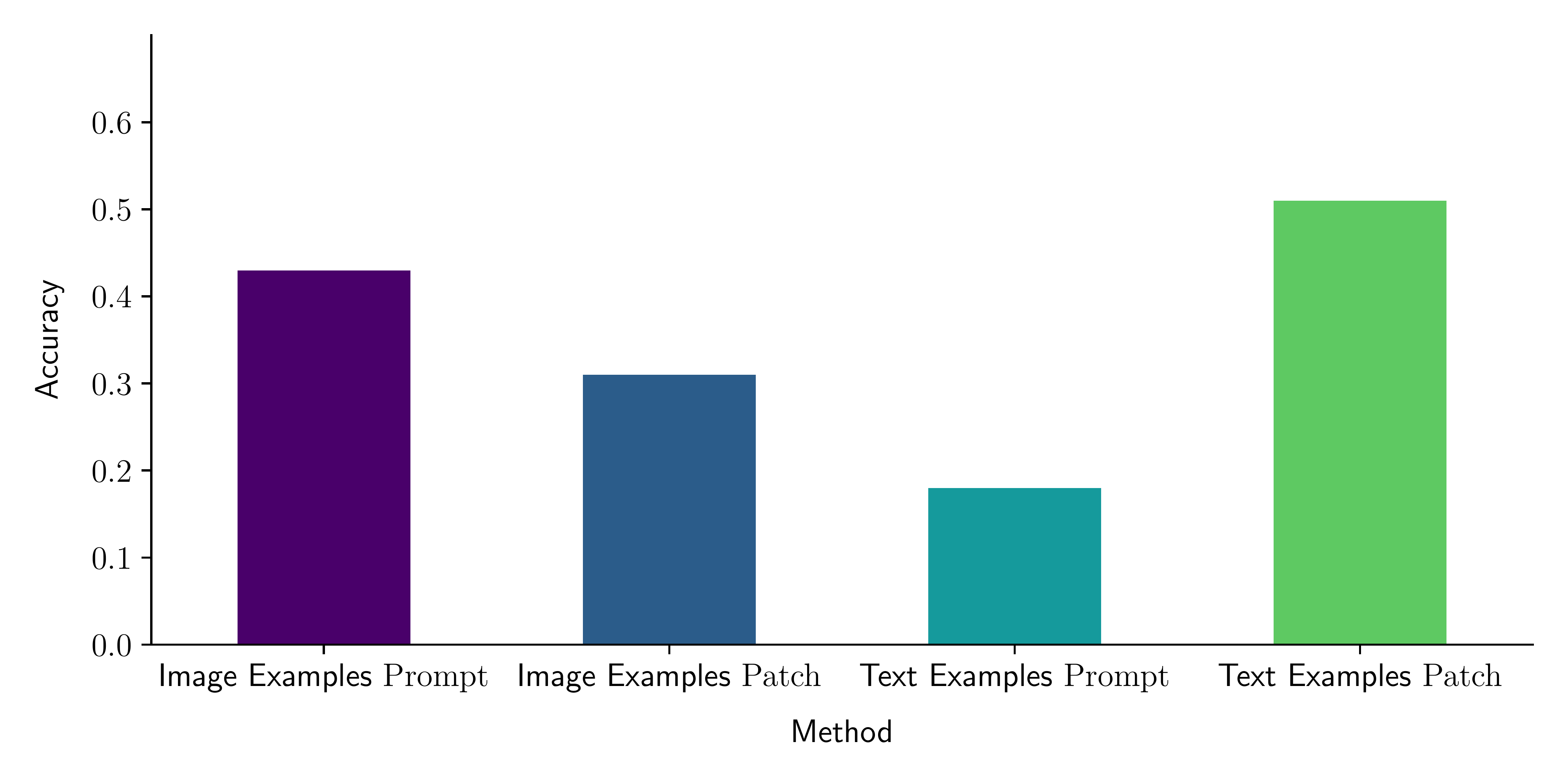
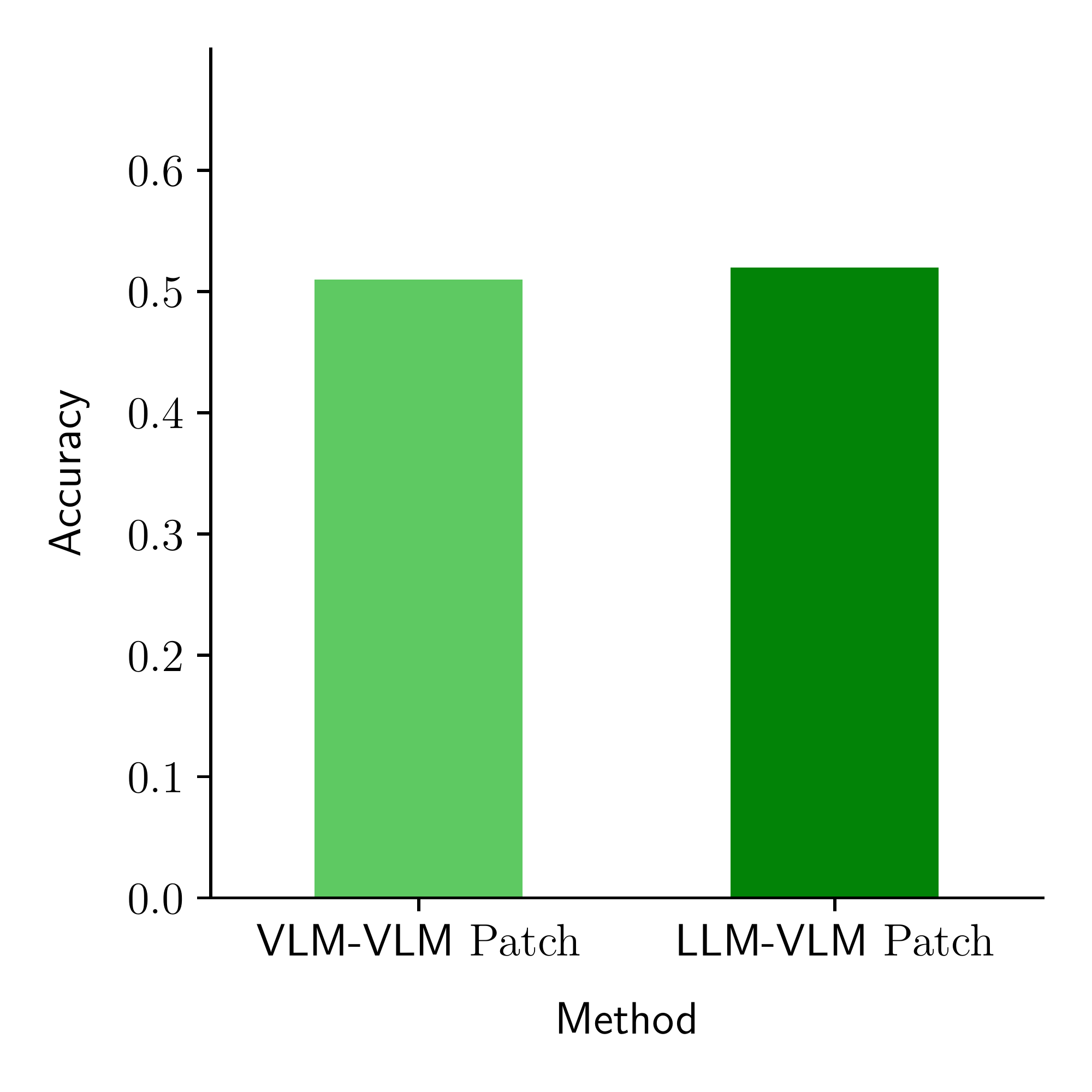
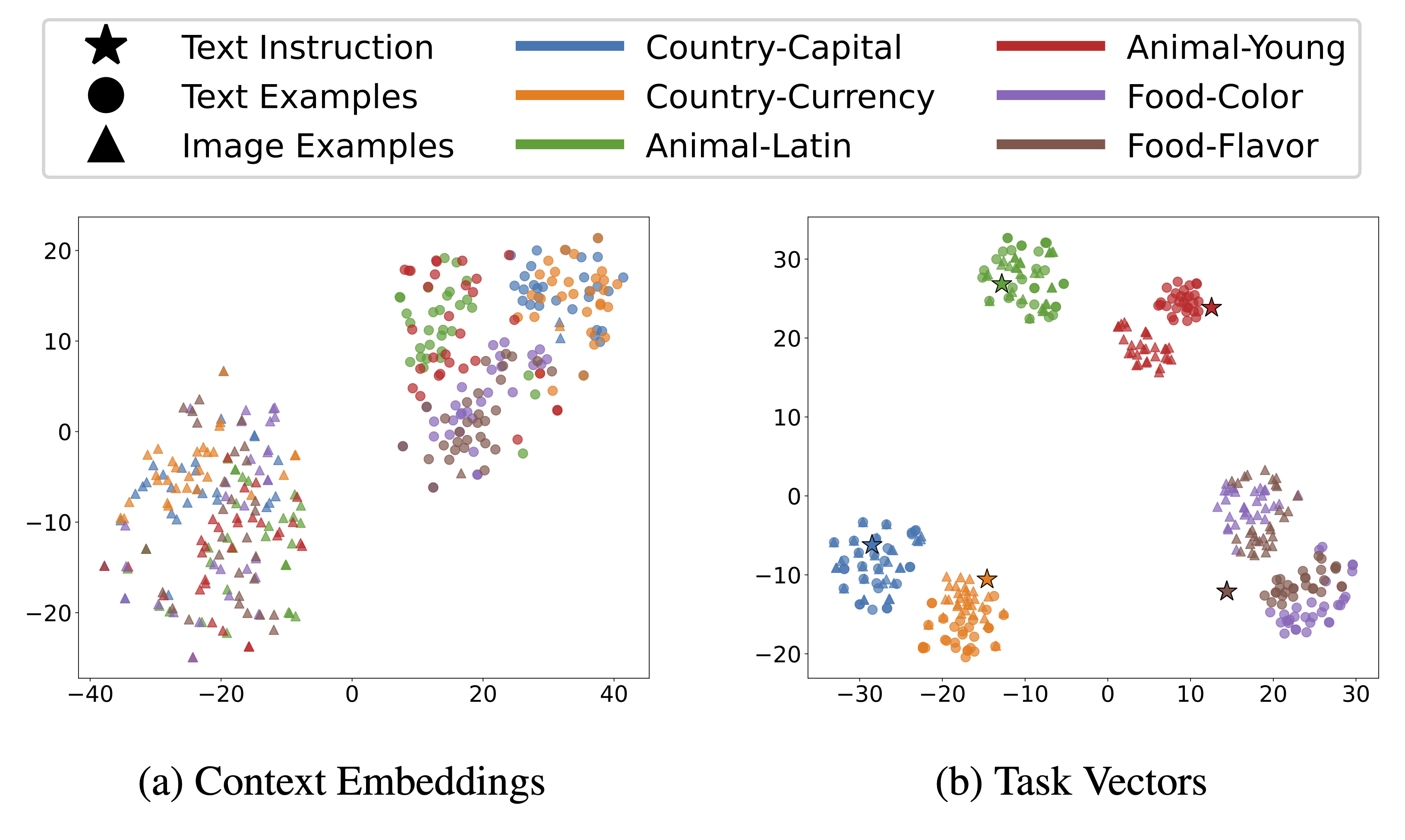
Cross-Modal Tasks
Task:
 Click the underlined text for dropdown menu
Click the underlined text for dropdown menu
| Instruction | Text ICL Example | Image ICL Example |
|---|---|---|
| The capital city of the country: | Greece : Athens |  : Athens : Athens |
| The last word of the official currency of the country: | Italy : Euro |  : Euro : Euro |
| The scientific name of the animal’s species in latin: | Gray Wolf : Canis lupus |  : Canis lupus : Canis lupus |
| The term for the baby of the animal: | Common Dolphin : calf |  : calf : calf |
| The color of the food: | Persimmon : orange |  : orange : orange |
| The flavor descriptor of the food: | Strawberry : sweet |  : sweet : sweet |
We design six tasks inspired by the text ICL examples proposed in prior work, where we add alternative specifications such as instructions and image examples.